
k-匿名算法是在LBS(location based services)中为了保护用户的位置隐私而形成的算法,它实际上是一个在服务的可用性和用户信息的隐私性之间做出了相互妥协的算法。并且,k-匿名算法一般要借助第三方的受信任的server来完成匿名过程
k-匿名算法的分类
- check-in cloaking(单一签到地点模糊化):加入k-1个属性相同的位置点,形成一个区域,进而保护用户的位置隐私
- sequence cloaking(填到序列或者查询序列模糊化):要求用户的签到序列(查询序列)至少与k-1个用户相同
k-匿名算法的缺点
- 冷启动问题
- 依赖于网络密度(针对于单一位置匿名这个问题可以用dummy位置来解决,但是序列匿名则需要扩大匿名范围,导致服务的可用性下降)
- 如果是单一位置匿名,可能会暴漏轨迹隐私,也可能被攻击者利用轨迹而缩小攻击范围
sequence cloaking
主要文章:
其主要对象是在公共场合使用轨迹匿名方法来保护用户隐私。 目标是使得 |T| 最小,进而是的服务的可用性得到保证
|T| = Sum[Area(C)]/n 其中Sum[Area(C)]为n个匿名区域的面积的和
KAT(K-anonymity trajectory)思想的具体定义如下
Definition 1: T is a KAT of T0, iff for each circle Ci in
T, the following conditions are satisfied:
1) Ci covers ci in T0, i.e., ci ⊆ Ci;
2) Ci covers at least one footprint in each additive trajectory;
3) For any Ci and Ci+1, there exist two footprints a[j,x]and a[j,y] in eachadditive trajectory Tj such thata[j,x]⊆ Ci, a[j,y]⊆ Ci+1, and x < y.
如下图所示:
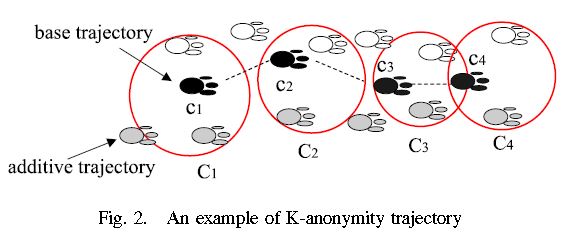
Cloaking One Additive Trajectory
对于K=2的情况下,需要把另一个用户(Additive)的轨迹与目标用户的轨迹模糊化。T0为目标用户的序列,T1为Additive用户序列,n、m分别使他们的长度,MBA(C,a)是覆盖这两个位置最小的圆形区域。算法如下:
1:p ← 0
2: for 1 ≤ j ≤ n do
3: M ←∞
4: for p < i ≤ m − n + j do
5: if M >Area(MBC(cj, ai)) then
6: M ← Area(MBC(cj, ai))
7: p ← i
8: end if
9: end for
10: Cj ← MBC(cj, ap )
11: p ← p
12: end for
13: T ← {C1, C2, · · · , Cn}